Frank recently told me about “quick” modal damping and explained it as “adding the modal damping forces to the right-hand side but not adding the modal damping terms to the dynamic tangent”.
The rationale for “quick” modal damping is to reduce computational expense due to:
- Assembly of modal damping terms into the dynamic tangent must be done at every iteration within a time step.
- The modal damping matrix is generally full regardless of the element connectivity.
- Modal damping terms do not change during a time step, and unless you call the
eigencommand during an analysis, the terms do not change at all.
You can use quick modal damping in OpenSees with the modalDampingQ command (note the Q at the end of the command name).
Consider the four-story rigid shear frame shown below, the same model used in a previous post on modal damping.

Note that the DOF numbers were defined out of sequence (1-3-2-4 from the bottom up) to see the effects of different matrix storage schemes.
After defining the model and performing an eigenvalue analysis, specifying 5% damping in each of the four modes is straightforward.
# Regular modal damping
ops.modalDamping(0.05)
# or Quick modal damping
ops.modalDampingQ(0.05)Imposing a unit value of roof displacement as an initial condition, the free vibration response history of the three floors and roof is shown below. Both modal damping and “quick” modal damping give the same response.
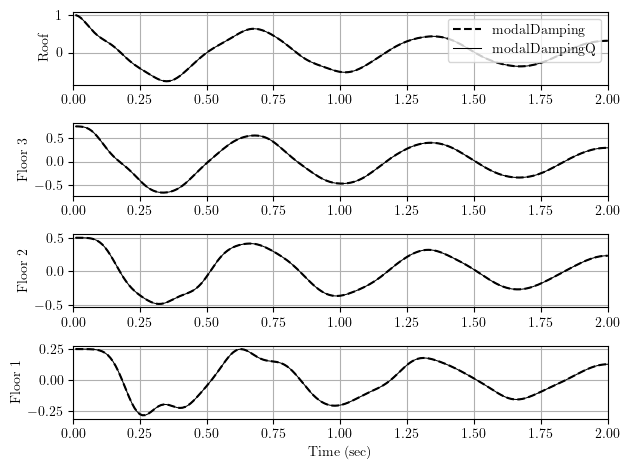
Because it provides storage for the full damping matrix, the FullGeneral solver is the only way to get convergence in one iteration at each time step when using modal damping with a linear model.
However, with “quick” modal damping, the damping matrix is not assembled and the dynamic tangent becomes inconsistent with the residual, i.e., there are damping forces, but the dynamic tangent only has mass and stiffness contributions. As a result, quick modal damping requires multiple iterations per time step for a linear analysis, no matter which solver you use. The Newton algorithm converges in seven iterations in the first time step of the shear frame analysis as shown below. You could cut that down to five iterations if you use KrylovNewton.
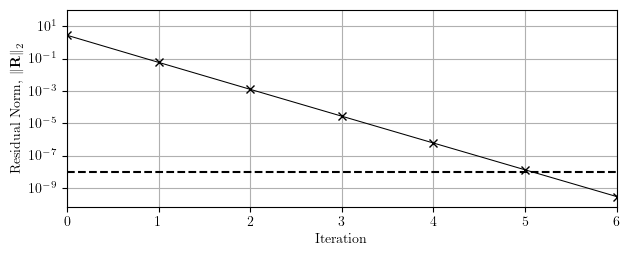
So, not only is quick modal damping quick, it’s also dirty.
But I’m making something out of almost nothing. Don’t read too much into or extrapolate these results for small models, where all of this is generally unimportant.
For large models though, forming the modal damping matrix is a big deal and the computational savings outweigh the additional iterations. For what size model? I don’t know. It depends. Besides, for nonlinear problems, changes in the static stiffness will dominate the convergence of Newton-Raphson or otherwise, making it unlikely that omitting the modal damping matrix by using “quick” modal damping will cost you any extra equilibrium iterations.

Hi Professor Scott,
Is there a way to extract the modeshapes and periods during a NLTHA with modal damping without altering the modal damping matrix?
Many thanks,
Nic
P.S. I want to congratulate you on your fantastic blog. I find your excellent use of small case studies and informal way to describing the results/findings really useful for helping me learn more about opensees, modelling and structural dynamics! Thanks so much!
LikeLike
Hello Nic,
Thank you for the positive feedback on the blog!
Regarding your question, no, there’s no easy way to keep the modal damping matrix unchanged while issuing the eigen command during a nonlinear dynamic analysis. You might be able to do something with zero length elements and elastic viscous materials like in https://portwooddigital.com/2025/07/27/bring-your-own-matrix/, but that could get complicated.
Michael
LikeLike