Although it has its proper uses, I’m not a fan of the linear algorithm. I’m even less of a fan of modal damping. However, it’s totally reasonable to use these two analysis options together–and if you do, watch out!
I’ll walk you through a recent encounter with this lethal combination, experienced during a live presentation on response history analysis of linear frame models.
Here is the displacement response history for bidirectional excitation of a 3D linear-elastic frame model. All elements are elasticBeamColumn and there is no damping.
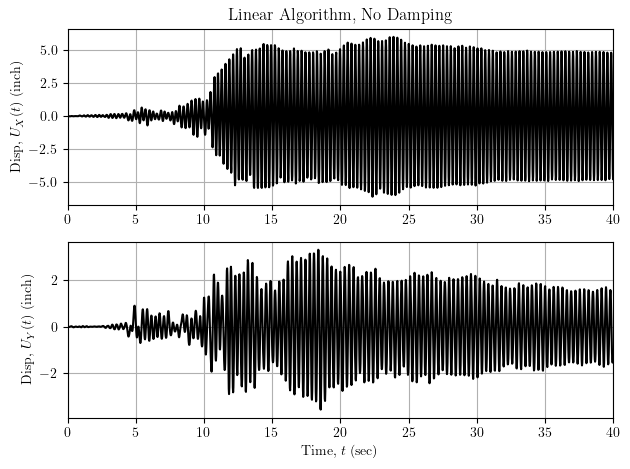
Someone asked, “What do the results look like with damping?” Put on the spot, I didn’t have time to find, copy, and paste into the script the code for computing the Rayleigh damping coefficients. Instead, I did modal damping by adding two lines to the script.
ops.algorithm('Linear')
# Simple addition to demonstrate damped response
ops.eigen(4)
ops.modalDamping(0.03)For a quick demonstration, 3% damping in the first four modes of vibration seemed reasonable. But the results were totally unreasonable.

After panicking for a few seconds, I remembered that modal damping messes with the topology of the effective stiffness matrix. And the linear algorithm is explicit, doing one linear solve then carrying any equilibrium error to the next time step. And there will be equilibrium error after one solve because modal damping makes the effective stiffness inconsistent with the residual force vector. And repeat.
With this negative feedback loop of modal damping and the linear algorithm, the computed response history becomes numerically unstable. There are two simple options to close the loop:
- Change the system to
FullGeneral; or - Change the algorithm to
Newton(or some variant)
Choose either option and the damped response history looks much better. I chose option 2 during the presentation.
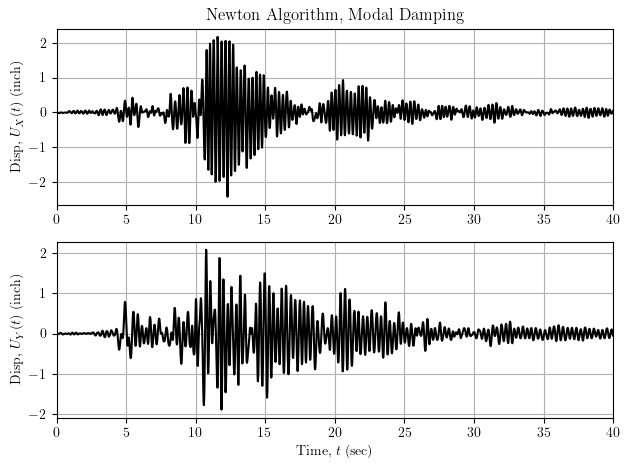
The advantage of option 1 is you can keep the linear algorithm; however, the FullGeneral solver can get expensive for larger models. With option 2, you can continue using a sparse solver, which can be relatively fast despite multiple Newton iterations; however, convergence with Newton is not guaranteed when using modal damping on linear models.
With either option, remember I’m talking about the analysis of linear models. For nonlinear models, you have to use Newton or one of its variants and this post is a non-issue.
